Amsterdam (NL), Starnberg, 27. Mai 2016 – Version 6 liefert Automatisierung, proaktive Reparatur, Amazon S3 Cross-Region Replication und Speicheranalysen…
Zum Hintergrund: wachsende Datenmengen im unstrukturierten Bereich und die damit verbunden Ausgaben sind auf Dauter nicht mit vorhandenen Budgets auf Basis klassischer (NAS / SAN) Technologien für die meisten Unternehmen beherrschbar (Systeme skalieren nicht kosteneffektiv, Backup-Restores dauern länger; Datenmigration auf neue Systeme ist sehr arbeitsintensiv; bei Provisionierung des Speichers muss häufig manuell nachjustiert werden). Es muss also überlegt werden, wie die Speicher-Infrastruktur geändert bzw. ergänzt werden kann, um diesem Wachstum gerecht zu werden. Für diejenigen Unternehmen, die einen hohen Anteil an unstrukturierten Daten haben, wird deshalb wohl kein Weg an Objektspeicher-Lösungen (1) vorbei führen.
Cloudian - ein Anbieter von Software Defined Storage und S3-kompatibler Objektspeicherung - hat hierzu die neue Version 6.0 seiner Objektspeicherlösung Cloudian HyperStore vorgestellt. Mit HyperStore können Unternehmen & Serviceprovider eine mit Amazon S3 kompatible Cloud-Speicherung erstellen, die lokal, mithilfe eigenständiger Software oder über integrierte Cloudian HyperStore-Appliances betrieben wird. So kann nach Angaben von Cloudian eine S3-kompatible Speicherung für ca. 1 US-Cent pro GB und Monat erreichen werden.
HyperStore 6.0 umfasst Funktionen, mit der sich Datenmengen im Petabyte-Bereich vereinfacht und kosteneffektiver verwalten lassen. Die Automatisierung unterstützt dabei, auch sehr große Kapazitäten zu verwalten: Funktionen hierzu beinhalten die proaktive Reparatur, Amazon S3 Cross-Region Replication für die Notfallwiederherstellung sowie intelligente Speicheranalysen. Cloudian HyperStore 6.0 ist laut Hersteller seit diesem Monat erhältlich; für Bestandskunden ist das Upgrade auf v.6.0 kostenlos.
Wichtige Leistungsmerkmale von HyperStore 6.0 im Kurzüberblick:
1. Widerstandsfähigkeit bei hoher Skalierung:
2. AWS S3 Cross-Region Replication verbessert die Leistung hinsichtlich Disaster Recovery und Compliance
3. Proaktive Reparatur
4. Dynamisches und automatisiertes Objektrouting
5. Proaktive Autokorrektur
6. Betrieb bei hoher Skalierung:
7. Spontanes Hinzufügen von Knoten
8. Upgrades im laufenden Betrieb
9. Automatische Servicewiederherstellung
10. Tuning bei hoher Skalierung:
11. Integrierte Speicheranalysen
12. Verwaltung von Clustern mit einer einfachen, Drilldown-fähigen visuellen Managementkonsole
13. Objektfinder
Anwenderzitat: „Widerstandsfähige Daten und zuverlässige Services sind unbedingt notwendig und sind der Schlüssel zur Zufriedenheit unserer Kunden“, betont J.J. Milner, Managing Director, Global Micro. „Wir haben uns für HyperStore entschieden, weil wir damit die notwendige Robustheit bei hoher Skalierung erhalten und zugleich dank der leichten Verwaltbarkeit effizient arbeiten können. Dies bedeutet maximales Umsatzpotenzial für unser Unternehmen.“
Zitat: „Wenn der Datenumfang von Unternehmen Petabytes erreicht, können die Betriebskosten schnell die Investitionsausgaben übersteigen. Nicht nur der physische Speicher kann untragbar werden, sondern auch die Ressourcenkosten für Verwaltung und Schutz der wertvollen Unternehmensdaten. Das Datenwachstum wird sich in absehbarer Zeit nicht verlangsamen, aber wir können eine bessere Möglichkeit finden, diese Daten zu verwalten“, erklärt Michael Tso, CEO und Mitgründer, Cloudian.
Datenblatt der Software Cloudian HyperStore (PDF)
Cloudian Blog zur neuen Version 6.0
(1) Anhang (Quelle Cloudian): Was zeichnet Objektspeicher aus, was ist der Unterschied zu bisherigen Technologien und welche Standards finden sich am Markt?
Wie arbeitet Objekt Storage?
- Objektspeicher vereint mehrere Charakteristiken. Zum einen wird das Speichern der Daten komplett von der Hardware losgelöst, auf dem sie gespeichert wird. Damit werden Daten mobiler, können sehr einfach migriert werden und stehen Applikationen einfacher zur Verfügung. Das Loslösen der Daten von der Hardware vereinfacht auch die Skalierung und erlaubt simple Integration und Entwicklung für Anwendungen.
- Objektspeicher ist sehr effizient – er braucht nur genau so viel Speicher wie die Datengröße, ohne aufwändige Voreinstellung von Daten-Containern. Objekte sind natürlich auch Daten, allerdings nur im Prinzip so wie Dateien. Anders als bei Dateien sind Objekte nicht hierarchisch organisiert, sondern existieren wie alle anderen Objekte auf dem gleichen flachen Speicherpool. Objekte können nicht innerhalb von anderen Objekten gespeichert sein und haben, genauso wie Dateien, Metadaten. Bei Objektspeicher sind diese Metadaten jedoch mit einem einzigartigen Identifizierungscode erweitert, der es erlaubt, das Objekt zu finden, ohne zu wissen, wo es gespeichert ist.
Welche Standards gibt es?
- CDMI, definiert und entwickelt von der SNIA, der Storage Industry Networking Association (noch geringer Verbreitungsgrad)
- OpenStack Swift Open Source API, der zunehmend von Herstellerseite unterstützt, um die Produkte kompatibel mit OpenStack Nova zu machen.
- Amazon S3 ist ein de-facto-Standard, wenn man die sehr große Anzahl von Anwendungen (>500) und den bereits hohen Verbreitungsgrad betrachtet.
+++ Hinweis in eigener Sache: Mehr zum Thema Objektdaten-Speicherung in der Praxis erhalten Sie in verschiedenen Anwender-/Herstellerbeiträgen im Rahmen unseres 17. Anwendertreffens am 16. Juni 2016 in Frankfurt/M. auf dem Gelände des e-shelter data-center campus +++
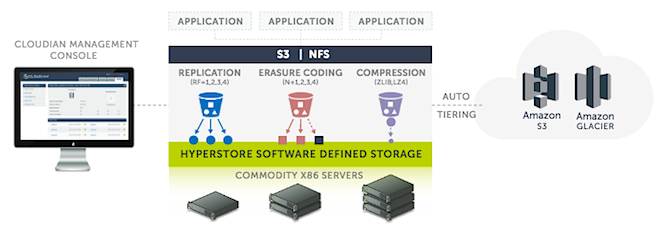
Abb. 1: Bildquelle Cloudian Hyperstore, Software Defined Storage