Starnberg, den 4. Dez. 2012 – Plattformunabhängiges verteiltes Filesystem für unterbrechungsfreien Datenzugriff und skalierbare I/O-Performance…
Zum Hintergrund: Wachsende Mengen unstrukturierter-, semi- oder polystrukturierter Applikationsdaten stellen Rechenzentren (inkl. Cloud Services Anbieter) vor Probleme. Die Daten kommen aus der Forschung (z.B. Pharmazie, Genom-Analyse), der Medienindustrie (HD-Filme), aus dem High-Performance-Umfeld (Astronomie, Physik, Biochemie), der Finanz-, Automobil- oder Konsumgüter-Industrie (Kaufverhalten, Crashtests, Marketingprogramme) bzw. aus Social Media Kanälen wie Google, Twitter oder Facebook (>70.000 neue Fotos weltweit pro Stunde). Klassische SAN-/NAS–Lösungen skalieren hier nicht effektiv, noch sind sie in diesem Umfeld kosteneffizient. Der Begriff "Big Data" fällt dann gerne in diesem Zusammenhang, wenngleich dies aus Anwendungssicht eher mit dem Business-Analytics-Aspekt (BI) zu tun hat. Jedenfalls ist die hierfür "richtige" Speicherarchitektur ein zunehmend kritischen Parameter, vor allem unter den Gesichtspunkten Wachstum, Verfügbarkeit, Kosten bzw. Ressourcenverwaltung.
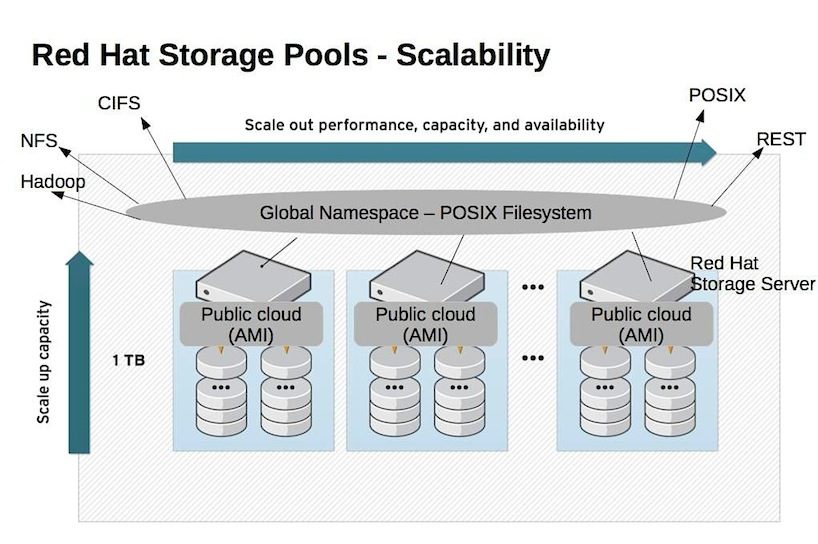
Die begrenzte Skalierbarkeit traditioneller Fileserver (nur Scale-up), verbunden mit zum Teil steigenden Kosten bzw. Einschränkungen beim Management komplexer Netzwerk-Storage-Umgebungen (Technologie-Silos, keine lineare Performance-Steigerung etc.) ist deshalb auch der Grund für eine neue Generation von File-basierten Storagelösungen: Red Hat liefert nun mit seinem Storage Server 2.0 hierzu einen offenen Lösungsansatz. Red Hat Storage Server 2.0 (resultierend aus der Red Hat Gluster-Aquisition, siehe auch: http://www.gluster.org ) ist ein Scale-out-NAS System inkl. global Namespace–Architektur, die den Aufbau eines logischen, zentral verwaltbaren Storagepools ermöglicht. Interessant ist die Tatsache, dass Storage Server 2.0 als distributed filesystem ohne Metadaten Server arbeitet (die spezifische File Name - Implementierung vermeidet Performanceprobleme).
Die Software unterstützt sowohl File- als auch Object Storage - Speicherung (POSIX-compliant, NFS, CIFS, HTTP) und kann als verteiltes File-System bis in den ZetaByte-Bereich skalieren. Damit positioniert sich diese open-source-basierte Lösung für "Much Data", also Multimedia-Applikationen, geophysikalische- oder astronomische Daten, financial analysis/modeling, medizinische Daten oder social media Data streams. Zwischenzeitlich wurde der Support für Big Data mit Apache Hadoop angekündigt. Der Red Hat Storage Server kann zusammen mit dem Hadoop Distributed File System (HDFS) oder an dessen Stelle eingesetzt werden und bietet neue Anwendungsbereiche für Hadoop bei File- und objektbasierten Anwendungen.
Weitere Quellen und Dokumente:
Ein neutrales, technisches Dokument zum erweiterten Object-Storage-Modell der SNIA als Standardisierungsansatz finden Sie übrigens in unserem Blog "Big Data und Cloud Object Storage Technologien" (siehe diese Webseite unter Rubrik "Blog") als PDF-Download (SNIA Document: A Cloud Environment for Data–intensive Storage Services).
Während unserer LRZ-Fachtagung Mitte November hat Red Hat die Architektur und wesentlichen Leistungsmerkmale seiner Lösung vorgestellt. Als registrierter Benutzer unserer Seite können Sie das zugehörige PDF-Dokument "Red Hat Storage Server 2.0 – File- und objektbasierter Speicher in und für die Cloud" - über unsere Rubrik "Downloads" herunterladen:
http://www.storageconsortium.de/content/?q=downloads
http://www.redhat.com/products/storage-server/
> http://www.storageconsortium.de/content/?q=node/1441
Bildquelle: Red Hat Storage Server, Nov. 2012